24 Jun 2018 - Kobi
At QED‐it, we have a mission to provide privacy preserving systems for the enterprise. For the last two years, we’ve worked on many projects, developing complex SNARK circuits and higher level protocols to tackle different use-cases - asset management, supply chain, real-time risk assessment, predictive maintenance, credit scoring and more.
We are happy to present one such project that has been done in collaboration with Deloitte. The project has been in the works for the last few months, in which the team in Deloitte utilized the QED‐it SDK to deploy a Zero-Knowledge Blockchain for their chosen use-case — new french tax rules presented in 2018.
Watch the talk by Jonathan Rouach, our CEO, at ZCon0:
Use-case
It is common for a person to purchase a life insurance contract from an insurer. The person then performs deposits to this contract. In “investment-type” contracts, these deposits are invested by the insurer in different investment vehicles, possibly earning gains.
At some point, the person would like to withdraw their money from the insurer. The question arises - how should these gains be taxed, before paying to the person?
This is where a friction point arises - the new 2018 french tax law binds the calculation of the tax to the accumulated value of all life insurance contracts held by the beneficiary.
When the person has contracts with a single insurer, then, naturally, all the data relevant for calculating the tax is held by this insurer. Since it is also possible for a person to purchase life insurance contracts from multiple insurers, a person might not want to expose this highly personal data to the insurer the person is withdrawing from.
What if we had a system, allowing a person to use all of the life insurance contracts from their insurers, and calculate the tax the insurer should pay, without leaking information about other contracts at other insurers?
Zero-knowledge proofs
Zero-knowledge proofs (ZKPs) allow a verifier to pose a question to a prover, and the prover answers this question, using whatever private data needed to answer it, revealing nothing more than the answer to the question itself.
An example of a question a verifier could pose is “do you know the solution to the following Sudoku puzzle?”. Obviously, the prover who knows the solution can show the solution itself. This prover, though, would like to keep the solution secret for now, but convince the verifier that they do know the solution. The prover can use a zero-knowledge proof to just answer “yes”! The cryptographic proof also serves for convincing the verifier that the right question was used on the right data and no one altered the result.
zkSNARKs are, amongst other properties, a way to do this process:
- Non-interactively - without a direct interaction between the prover and the verifier.
- Succinctly - the proofs are very small.
Explaining zero-knowledge proofs in depth is beyond the scope of this post, and if you wish to know more, I invite you to check out the following resources:
- Trustless Computing on Private Data - blog post by QED‐it’s lead cryptographer Daniel Benarroch and Prof. Aviv Zohar.
- Prove-it, Blockchain-it: ZKP in Action - a video of a meetup explaining ZKPs and how to create one for Sudoku.
- The Incredible Machine - blog post by QED‐it’s Chief Scientist Prof. Aviv Zohar, explaining trusted setup.
- The Hunting of the SNARK - a series of riddles to experiment with ZKPs.
The project
QED-it SDK
At the heart of the QED‐it SDK is an identity protocol. This protocol serves as a framework for committing to data by issuers, attesting pieces of data about a user, and allowing an auditor to pose audit questions to this user. The user, in turn, generates a zero-knowledge proof that combines the data inputs and uses a computation on them to answer the audit question.
The QED‐it SDK provides this protocol adapted to families of use-cases, especially the ones discussed and deemed important in the recent Zero Knowledge Proof Standardization workshop. The adaptations includes a set of building blocks for each of these families, allowing an auditor to pose increasingly complex audit questions.
Why is it called an SDK? Well, the SDK allows developers to write “hooks” - their own audit questions using a Domain-Specific Language. The encompassing protocols provide the security guarantees required by most of the use-cases.
High-level design
Let’s start with a diagram describing the system:
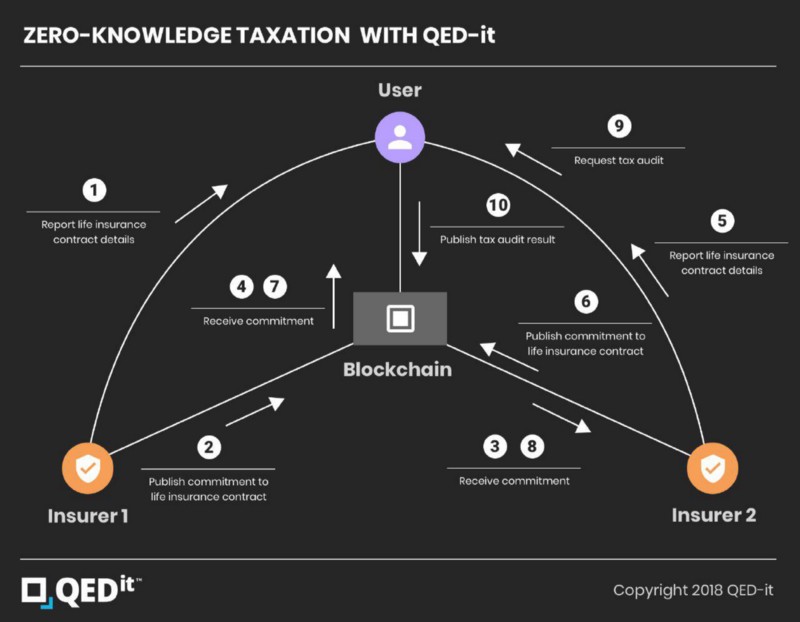
User, Insurer 1 and Insurer 2 are QED‐it nodes. The nodes give the ability to publish commitments about bits of data and generate ZKPs in response to audit questions.
Step-by-step (using the numbering of the diagram), this is how a possible system communication scenario looks like:
-
Insurer 1 sends the life insurance contract to the user, attesting to the contract between them.
-
Insurer 1 publishes commitments, in the form of hashes, of the contract. These are small values not exposing any information about the contract itself.
-
(This covers 3-8). The commitments are propagated throughout the network. Additionally, Insurer 2 does the same publishing steps as Insurer 1.
- The user requests to leave Insurer 2. The insurer has to pay the gains to the user, minus the taxes owed for them. In order to know the tax amounts, the insurer poses an audit question to the user - “given your life insurance contracts at all of your insurers, what is the tax amount that should be paid for the gains for the deposits you made to us?”
-
The user collects all their life insurance contracts, and generates a zero-knowledge proof of the calculated tax amounts.
- After receiving the ZKP, Insurer 2 pays the user, minus the taxes on the gains according to the law, all this without knowing any details about the other life insurance contracts the user holds! (Except, of course, what can be inferred from the audit question itself)
I’d like to highlight an important fact which may not be obvious - throughout this process, the data, once collected by the user, never left the user’s node! Still, the user can calculate by themselves the tax rates, with the insurer being certain that the result is correct.
In a centralized world, in order for the insurers to comply with the law, they must have more information, and so the user usually provides it to them. In the QED-it world, it’s not like that anymore! The users perform the math on their own machines, and they just need the right infrastructure to support this - users running QED-it nodes to generate ZKPs and insurers committing data and verifying proofs.
Modularization and Domain-Specific Language (DSL)
QED‐it’s SDK allows users to write their “business-logic” proofs both in our embedded DSL and and other external DSLs - languages for the domain of Zero-Knowledge Proofs.
The main requirement for this integration is that the proofs conform to the proof-chaining specification. Proof-chaining is a technique we’ve implemented that allows a prover to connect different proofs parts, even between different proof systems. This allows the DSL proofs to be connected with the other parts of the QED‐it’s proofs and protocol.
A bit more in-depth, the proof in this use-case is modularized to multiple proofs, “glued” together:
- Data validity proofs. These promise:
- The data has been published before by one of the approved parties, and existed by block X, referenced by a “merkle root” of the merkle tree generated by all the published commitments.
- The data has not been revoked by block Y.
- The subset of the data that will be chained to the next proof has been generated correctly, referenced by a hiding commitment to it.
As you may notice, we’ve introduced a new concept here, a Merkle tree. Specifically, the commitments in the system are collected in an append-only Merkle tree - a data structure that has efficient proofs for “set membership” -given a set S and an element x, you can efficiently show x is an element in the set S.
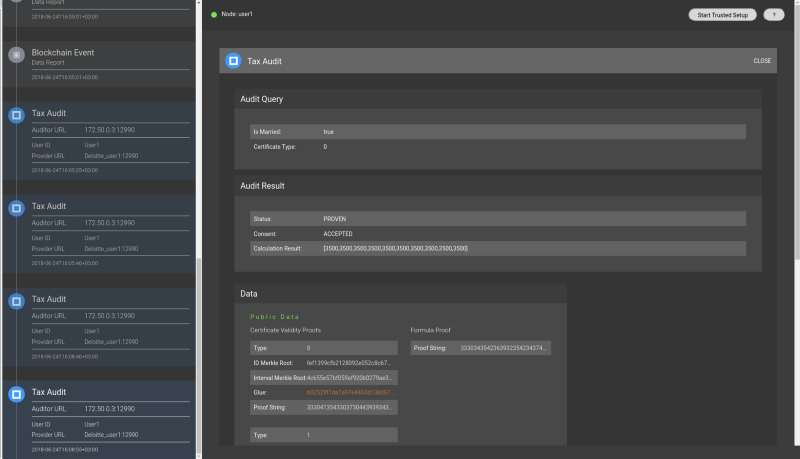
- Tax proof. This is the proof containing the specific business logic of the proof, which in this case means the calculation of the tax amounts. This proof assumes the data inputs have been validated by other proofs. This assumption causes this proof to be very small and efficient!
The different proof components are connected by what we call a glue.
The verification protocol then, in addition to verifying that the merkle roots existed in the past, includes verification of the “glue” components between the different proofs.
The calculation of tax amounts in the Tax Proof has been written by Alizée Faytre, who has been the developer in Deloitte working on the project under the supervision of Ossama Benbouidda and Julien Maldonato, using ZoKrates — a Python-like high level language that compiles into zkSNARKs.
External verifiers
An important part of this project was allowing an external party who is not running a QED‐it node to enjoy the results of the zero-knowledge proof generated by the user’s QED‐it node.
To do that, we chose to deeply integrate with an Ethereum network, which, since the Byzantium hard-fork, allowing zkSNARKs proofs verification by providing precompiles for efficient evaluation of elliptic curve operations on the BN128 curve. In short, this means that we can generate proofs using a QED-it node and verify them in a decentralized manner on the Ethereum blockchain.
We implemented a smart contract that essentially acts as an autonomous verifier. This smart contract allows the different parties to publish commitments that will be collected in an incremental merkle tree, and run the verification protocol on the bundle of proofs generated by the user.
This allows, for example, for a smart contract managing the wallet of the insurer, to consume the tax proofs, pay the taxes to the government and pay the user minus the tax. This coincides with our vision of real-time regulation compliance.
The system in action
We deployed the system comprising a set of 6 nodes - 5 insurers and 1 user, running a Proof-of-Authority Ethereum network. These parties run QED‐it nodes and have the ability to generate these proofs, using our own efficient data validity proofs and to generate the tax proof using ZoKrates.
The nodes are easily deployable using Docker and are exposing an HTTP API to be easily integrated with.
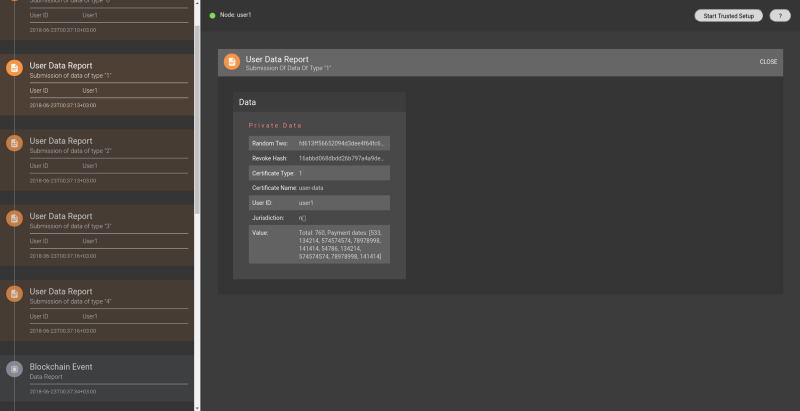
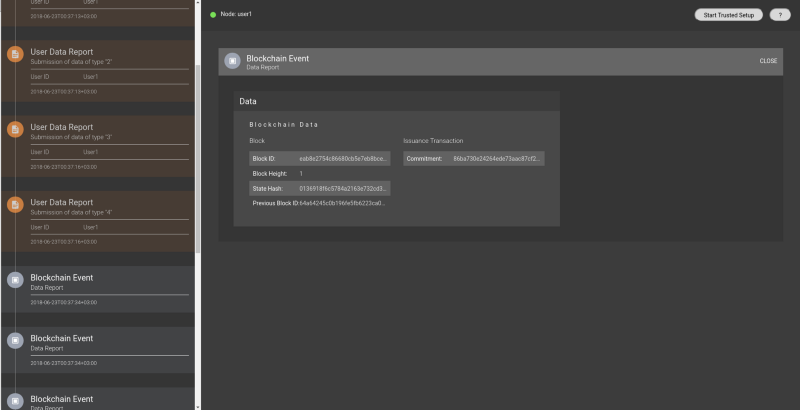
Along with its node, comes QED-it’s explorer tool, that realizes our vision of a ZKP monitoring system and allows operators of nodes to monitor the activity of their nodes, just like a block explorer allows one to monitor a blockchain. This is how the process looks like there:
- Data report by an insurer:
- Commitment publish by an insurer:
- Tax calculation result:
Challenges
This project uses bleeding-edge technology, and as you can imagine, it posed a few challenges:
- The smart contract implementing the autonomic verifier has to maintain a history of “known merkle roots” - each time a commitment is published to the contract, the new root should be calculated and kept.
Doing this naively is an issue - as this is an incremental tree, commitments are never deleted, so it’s best to use as large as possible tree. We chose a tree of depth 30, supporting about a billion of commitments. Managing this large a tree directly in a smart contract is not practical.
To cope with that, we implemented an efficient incremental merkle tree in Solidity.
- The gas requirements for the pairing operations needed to verify proofs are pretty high - verifying a single proof consumes about 2 million gas.
This is where the different trade-offs between the systems come into friction - on the one hand, modularization of proofs allows for more versatile, practical and secure proofs, and on the other hand, we would like to minimize the amount of gas used in the contract.
There are possibilities to make good trade-offs - using different modularization techniques, combining proofs using Proof-Carrying Data and many more. In a private Ethereum network, it even becomes a non-issue, with the ability to introduce new precompiles.
Also, there are proposals to decrease the amount of gas, which will improve this situation.
- The glue component in the tax proof requires the use of hashes in ZoKrates. We have made efforts to integrate efficient external circuits and are hoping to collaborate with the ZoKrates team to make more integration possibilities a reality.
Summary
In this post, we’ve seen an end-to-end zero-knowledge system to allow real-time taxation with exposing the user’s private data. This is just scratching the surface of the possibilities of practically using zero-knowledge proofs and other privacy preserving tools, in which we specialize in QED‐it.
Of course, many technical details have been omitted for brevity, and there’s much more to the story. I invite you to write to us at [email protected] to learn more about the SDK.
If you’re attending ZCon0, you’re welcome to meet some of our team and attend our CEO’s talk about “Zero Knowledge In The Enterprise” on day 2 at 9:10AM and the ZKProof workshop on the same day at 1PM, lead by our Daniel Benarroch and Eran Tromer.
We are also hiring!
I hope this has been enjoyable, and that it ignites the imagination as to what is now possible in a privacy preserving world!